KRAKÓW |11 PAŹDZIERNIK 2020 R.

KRAKÓW |11 PAŹDZIERNIK 2020 R.
Daniele Vergari i Cristina Caprara - CRIF
Bankowość otwarta a cyfrowa rewolucja
Wejście na rynek finansowy nowych graczy i innowacyjne praktyki angażowania klienta mogą być również motorem podstawowych zmian wpływających na przebieg procesów kredytowych. W tym kontekście stosowanie technik machine learning zapewnia zasadniczą przewagę konkurencyjną, przyspieszając działanie narzędzi decyzyjnych wykorzystywanych do zarządzania procesami kredytowymi i poprawiając ich skuteczność.
Ostatnio opracowane techniki LIME, wykorzystywane do interpretacji modeli machine learning w połączeniu z już wdrożonymi technikami profilowania danych umożliwiają również pokonanie znanych ograniczeń interpretowania wyników i ułatwiają ich stosowanie zachowując zgodność z regulacjami. Firma CRIF przeprowadziła badanie oraz przygotowała opracowanie przedstawiające wyniki algorytmu automatycznego wyboru zmiennej (Model Feature Selection - MFS), na podstawie wcześniej wspomnianych technik. Zadaniem tego algorytmu jest wydobycie maksymalnej wartości z danych pochodzących z coraz liczniejszych źródeł oraz zoptymalizowanie opracowywania i walidacji narzędzi statystycznych, wykorzystywanych do szacowania ryzyk w procesie kredytowym.
WSTĘP
Dotychczas w bankowości nie stosowano powszechnie technik machine learnig do zarządzania ryzykiem kredytowym z dobrze znanych przyczyn: modelom towarzyszą trudności interpretacyjne, a ponadto wymagają one wysoce wyspecjalizowanych umiejętności technicznych. Z drugiej strony, rynek konkurencyjny zmienia się: transformacja cyfrowa, wejście w życie dyrektywy PSD2 oraz nowy model bankowości otwartej znacząco wpływają na praktyki zarządzania ryzykami.
Pojawienie się nowych graczy, w tym FinTechów, oraz rozwój nowych praktyk angażowania klientów, jak również gwałtowny wzrost ilości dostępnych informacji (ustrukturyzowanych i nieustrukturyzowanych), prowadzą do nieuniknionego odejścia od tradycyjnego nastawienia do zarządzania danymi. Z tej przyczyny wzrasta konieczność poszerzania zakresu stosowania innowacyjnych technik z wykorzystaniem machine learning, identyfikujących źródła interpretacyjne do algorytmów, poprzez pokonanie przeszkód, które dotychczas ograniczały możliwość ich wykorzystania. Modele machine learning umożliwiają wyliczanie współczynników syntetycznych, efektywnych i dynamicznych, co pozwala podejmować świadome decyzje w środowisku konkurencyjnym, charakteryzującym się coraz większą zmiennością. Techniki te stanowią potencjalnie najlepsze metody efektywnego uzyskiwania wartości z danych, gdy celem jest skrócenie czasu analiz, zmniejszenie swobody decydowania w ramach procesu, udoskonalenie opracowywania i walidacji modelu oraz uzyskanie efektywnych wskaźników ryzyka, co zapewni stabilną przewagę konkurencyjną, dzięki coraz bardziej ukierunkowanemu i aktywnemu zarządzaniu portfelem klientów.
Jednym z najciekawszych potencjalnych zastosowań tych technik jest analiza i dobór zmiennych podczas wstępnych prac związanych z opracowaniem modelu. Faza ta staje się coraz bardziej złożona ze względu na większą dostępność źródeł informacji. Obecnie zakres bazy danych wykorzystywanej do oszacowania zdolności kredytowej jest nieskończenie większy i bogatszy niż jeszcze kilka lat temu. Obejmuje on również informacje niestrukturyzowane, na przykład dane geograficzne czy informacje pochodzące ze stron internetowych firm.
W tym kontekście techniki machine learning okazują się wyjątkowo przydatne do zarządzania coraz bardziej złożonymi informacjami, ponieważ:
Jednakże udoskonalone zarządzanie informacjami pod kątem zdolności prognostycznych (na przykład zdarzeń takich, jak zwłoka w płatności czy trudna sytuacja finansowa), nie jest ich jedyną zaletą. Metody te, w połączeniu z wykorzystaniem sztucznej inteligencji, umożliwiają uproszczenie całego procesu opracowywania modelu prognostycznego.
Grafika numer 1 pokazuje etapy, dla których zastosowanie innowacyjnych technik zarządzania danymi może przynieść znaczące udoskonalenia w ramach tradycyjnego sposobu opracowywania modeli identyfikacji oraz szacowania ryzyka. Przedstawione tutaj badanie koncentruje się na zastosowaniu metody Random Forest - tzw. las losowy (RF, patrz Breiman 2001), która pozwala zredukować liczbę zmiennych umieszczonych w długim wykazie i otrzymać wykaz skrócony.
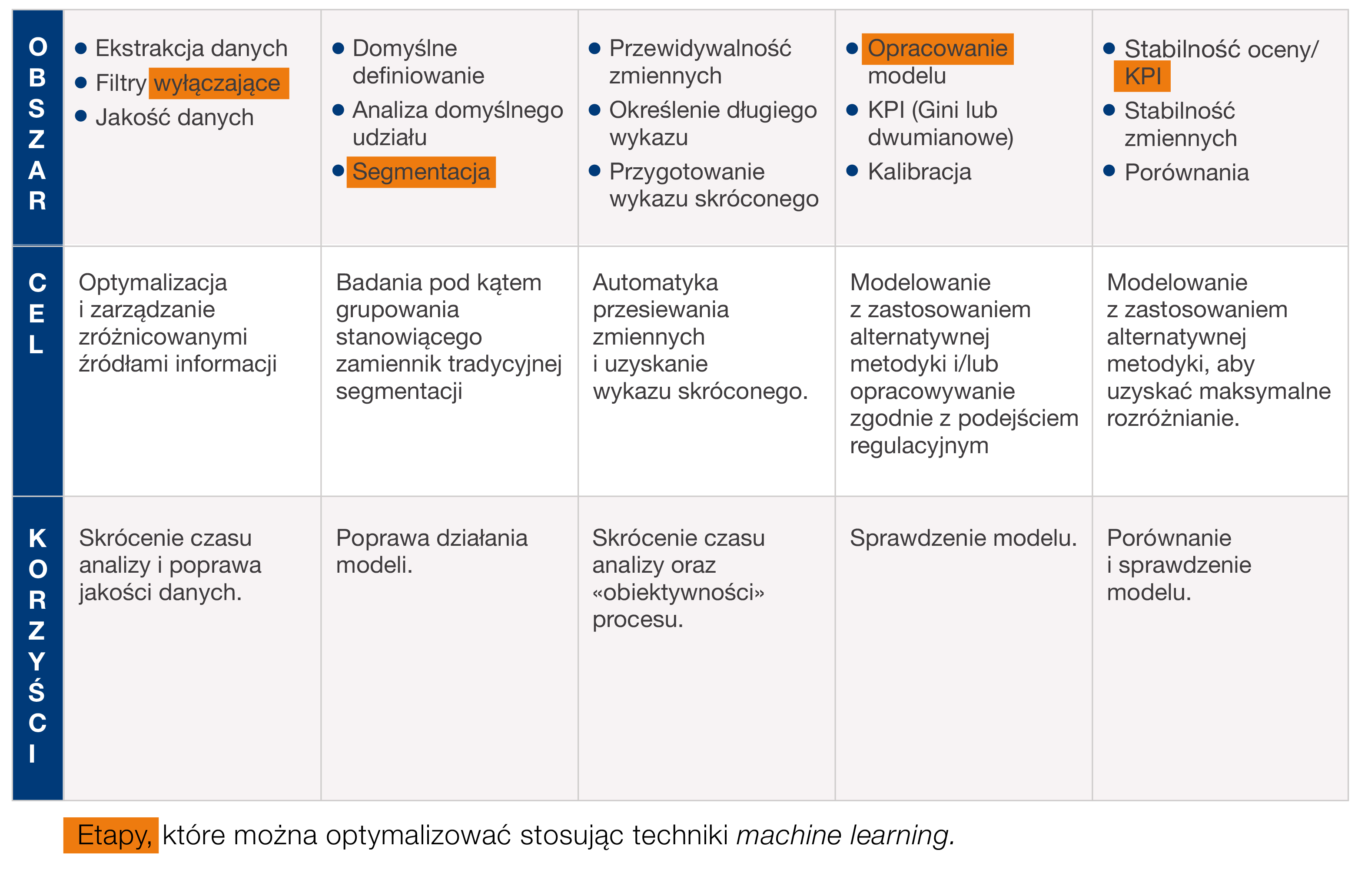
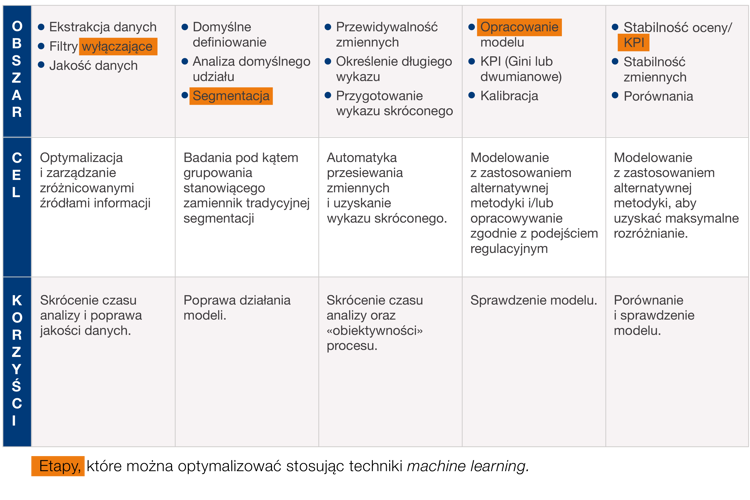
Grafika 1: Fazy, które można zoptymalizować stosując techniki machine learning i sztucznej inteligencji
Nowa metodyka umożliwia przemyślenie całego procesu opracowywania i utrzymywania systemu modeli prognostycznych (na przykład zaawansowanych modeli ratingowych lub modeli zarządzania), od stworzenia analitycznej bazy danych poprzez segmentację, aż do zbudowania modelu końcowego i jego walidacji.
Z kolei brak możliwości natychmiastowego określenia czynników na potrzeby szacowania ryzyka przez modele machine learning (umieszczające analityków i nadzorujących przed black box, zwany „czarną skrzynką”) pozostaje główną przeszkodą w zastosowaniu ich w kontekście regulacyjnym.
Firma CRIF opracowała algorytm wyboru zmiennej (Model Feature Selection - MFS), który optymalizuje wybór zmiennych prognostycznych, począwszy od wykazu długiego, a jego podstawą jest szerokie zastosowanie tzw. lasu losowego. Algorytm sprawdzono w badaniu porównawczym przeprowadzonym na dużej próbie kontrahentów biznesowych (firmy spoza sektora finansowego) w kontekście opracowania rozwiązania wczesnego ostrzegania (early warning), pozwalającego przewidzieć i zaklasyfikować transakcję do stage 2[1], zgodnie z wymaganiami standardu rachunkowości MSSF 9. Wyniki porównano z „tradycyjnym” podejściem do doboru zmiennych, które rozpoczyna się od długiego wykazu predyktorów i, poprzez różnorodne działania, poczynając od analizy jednoczynnikowej, aż do korelacji wieloczynnikowych, przygotowuje wykaz skrócony wykorzystywany do oceny modelu statystycznego (Tabela 1). Przejście od wykazu długiego, obejmującego setki, a czasem nawet tysiące zmiennych, do wykazu skróconego, na który zazwyczaj składa się kilkadziesiąt danych, stanowi jeden z najbardziej wymagających etapów opracowywania modelu, jak również jest to jedna z faz, w której najczęściej analitycy podejmują decyzje uznaniowe.
[1] Zgodnie z wymaganiami prawnymi, „stage 2” obejmuje pożyczki charakteryzujące się znaczącym wzrostem ryzyka ocenianego na potrzeby tworzenia rezerw na cały okres funkcjonowania.
Ponadto podejście tradycyjne często faworyzuje relacje liniowe, podczas gdy algorytm MFS umożliwia również efektywne uchwycenie trendów nieliniowych. Zatem algorytm wyboru zmiennej modelu (MFS) zapewnia większą automatyzację, obiektywność i kompletność procesu analizy wieloczynnikowej, zmniejszając potencjalne błędy oraz margines subiektywności oceny. Podstawę algorytmu MFS stanowi generowanie bardzo dużej liczby „drzew decyzyjnych” lasu, w obrębie którego wybierane są zestawy zmiennych wykazujących najwyższą zdolność przewidywania klasyfikacji do stage 2.
Las w liczbie 500 drzew decyzyjnych[2] wygenerowano, aby zidentyfikować te połączenia zmiennych, które charakteryzują się najwyższą siłą prognostyczną, gwarantują poziom wzajemnych korelacji poniżej określonego progu oraz w największym możliwym stopniu przyczyniają się do prognozowania zdarzenia docelowego. Wielkość lasu jest niezwykle duża w porównaniu z praktycznym zastosowaniem tych modeli, co gwarantuje wiarygodność i solidność wyników końcowych.
Poprzez takie symulacje i przy odpowiedniej analizie wrażliwości pozwalającej określić parametry algorytmu, wyjściowy długi wykaz można zredukować do wykazu skróconego obejmującego poniżej 30 zmiennych, najpierw wybierając drzewa decyzji, które mają najwyższą zdolność prognostyczną, o współczynniku Giniego powyżej 70%, a następnie podzestawy wskaźników charakteryzujących się wysoką zdolnością prognostyczną, które nie są nadmiernie skorelowane.
Jedną z najistotniejszych obserwacji z badania jest stwierdzenie, że nowy wykaz skrócony utworzony z użyciem algorytmu MFS w 80% pokrywa się ze zmiennymi w tradycyjnym zestawie skróconym, a rozbieżność pomiędzy tymi dwoma listami w zakresie użytych zmiennych nie wpływa na działanie modelu.
Poniższa tabela przedstawia wskaźniki efektywności modelu wczesnego ostrzegania (early warning) uzyskane w trzech symulacjach statystycznych przeprowadzonych na bardzo szerokiej próbie ponad 600 000 włoskich firm, pobranej anonimowo z systemu sprawozdawczości kredytowej CRIF (EURISC). Dla tych kontrahentów, którzy w czasie analizy próby charakteryzowali się aktywną historią kredytową, zidentyfikowano wczesne znaki ostrzegawcze, zdefiniowane jako opóźnienia w płatnościach przekraczające 30 dni, które wystąpiły w ciągu pół roku od obserwacji w formie nierealizowania aktualnych zobowiązań finansowych lub wykorzystywania kredytów odnawialnych w stopniu przekraczającym ustalone limity.
[2] Symulacje przeprowadzono wykorzystując pakiet Ranger w programie R.
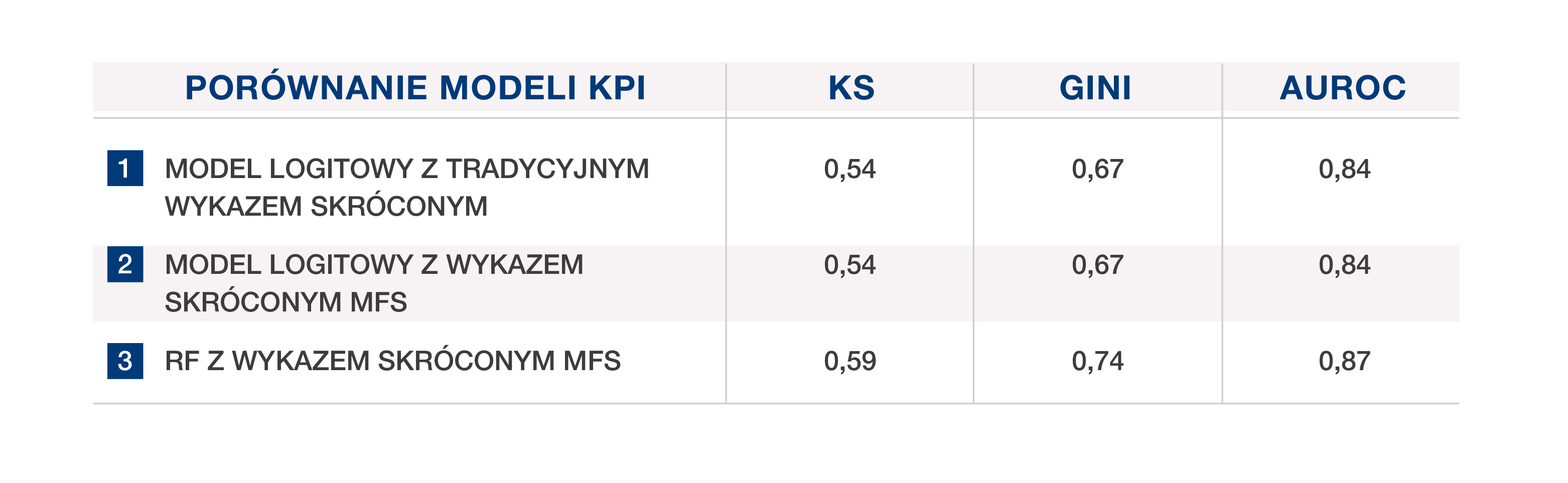
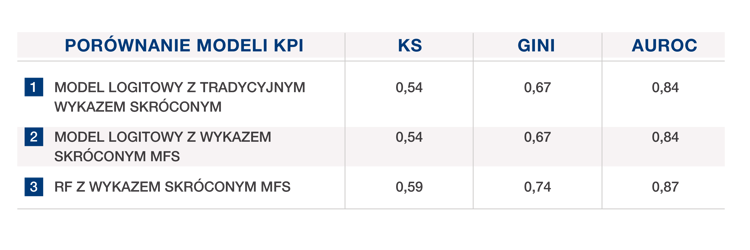
Tabela 1 porównuje trzy różne modele prognostyczne:
Wskaźniki efektywności modelu 2 są zbliżone do modelu 1. Najlepszą efektywnością charakteryzuje się las losowy (random forest), co można wyjaśnić faktem, że sumuje on pewną liczbę drzew decyzyjnych, w ten sposób wykorzystując i maksymalizując informacje dostarczane przez zmienne prognostyczne, łącząc je w odmienny sposób (indywidualny model logitowy nie zawsze może uzyskać takie wyniki).
Lepsza efektywność modelu lasu losowego (random forest), w porównaniu z modelem logitowym, jest również wyraźnie widoczna na krzywych ROC przedstawionych na Wykresie 1.
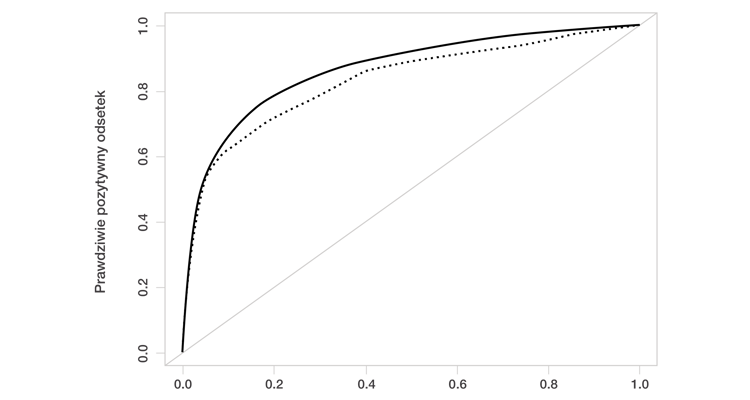
Wykres 1: Analiza porównawcza działania modeli - krzywe ROC
Generowanie wykazu skróconego technikami MFS może zatem skutecznie wspierać zarówno opracowywanie modelu, jak i fazy walidacji, umożliwiając - bardzo szybko i przy wykorzystaniu ograniczonych zasobów - identyfikację podzestawu zmiennych, pozwalającego najefektywniej przewidzieć badane zjawisko.
Niniejsza analiza przypadku podkreśla lepsze wyniki osiągane przez model lasu losowego (random forest). Jednakże modele tego typu były czasem przedmiotem krytyki. W porównaniu z podejściem tradycyjnym, którego podstawę stanowi np. funkcja logistyczna, uważano je za mniej przejrzyste jeżeli chodzi o interpretację wyników (a w szczególności rolę odgrywaną przez różne predyktory w wyznaczaniu wyższego lub niższego ryzyka zwłoki w przypadku określonego dłużnika). Aby pokonać te ograniczenia oraz „otworzyć tak zwaną czarną skrzynkę” (ułatwiając interpretację i zrozumienie wyników) zastosowano technikę LIME. Pozwala ona wytłumaczyć na poziomie lokalnym, tj., pojedynczej osoby, czynniki determinujące prawdopodobieństwo zwłoki przypisane przez model lasu losowego (random forest), a zatem pod względem leżącej u jej podstaw logiki jest podobna do punktacji modeli parametrycznych.
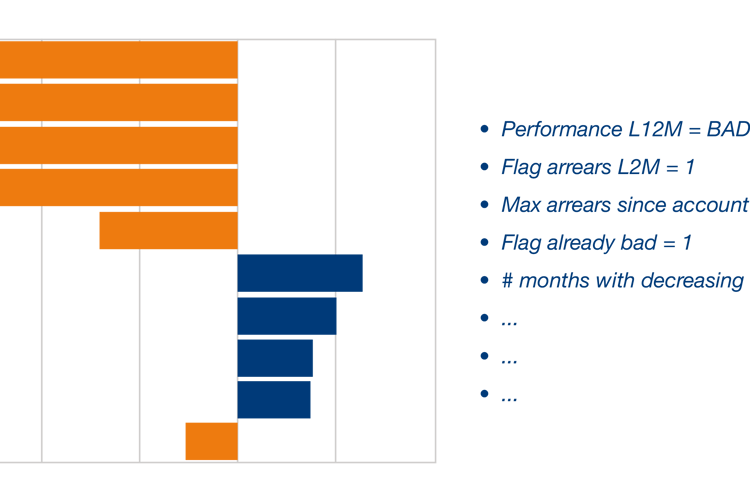
Grafika 2: Przykład zastosowania techniki LIME
Grafika numer 2 przedstawia przykład zastosowania techniki LIME do przypadku firmy, której las losowy (random forest) przypisał 75% ryzyko przejścia do „stage 2”. Wykres pokazuje wagę kluczowych zmiennych, które złożyły się na ten wynik: w szczególności, chociaż dłużnik w dniu oceny został sklasyfikowany jako realizujący swoje zobowiązania, w przeszłości miał istotne problemy, które zostały zidentyfikowane przez trzy pierwsze zmienne prognostyczne. Wyjaśniają one zachowanie modelu oraz przypisanie bardzo wysokiego ryzyka zwłoki.
Technika LIME umożliwia zatem wyjaśnienie wyników lasu losowego (random forest) na poziomie indywidualnym, ułatwiając ich interpretację i uzasadnienie przez osoby opracowujące i walidujące modele, ale również w konsekwencji przez sieć dystrybucji / sprzedaży wykorzystującą te uzasadnienia do zarządzania relacjami z klientami. W rzeczywistości praktyka przedstawiania osobom decyzyjnym główne przyczyny lub czynniki wpływające na ryzyko, które uzasadniają wyniki uzyskane w systemie oceny, umożliwiając na przykład podanie przyczyn nieprzyznania kredytu.
Technika LIME przedstawia dokładnie te same oceny, które stanowią podstawę wyników uzyskanych przez las losowy (random forest) i ułatwia ich zastosowanie w ramach wstępnej oceny kredytowej.
Badanie przeprowadzone przez firmę CRIF podkreśla możliwość uproszczenia fazy opracowywania modelu dzięki technikom machine learning, oferującym użyteczne wskaźniki odniesienia podczas działań walidacyjnych oraz maksymalizującym wartość wszystkich dostępnych informacji o próbie. W tym zakresie umożliwiają one również włączenie najbardziej innowacyjnych i nieuporządkowanych źródeł danych, ułatwiając szybki wybór podzestawów zmiennych, co zapewnia wysoką efektywność niezależnie od techniki (np. logistyczna czy las losowy) wykorzystanej do zbudowania modelu prognozowania zwłoki.
Przetestowany algorytm opracowano w kontekście procesów zarządzania ryzykiem, ale można go również stosować w innych obszarach jak np. do profilowania klientów czy systemów wspierających strategie obsługi klienta.
Przedstawione techniki skutecznie reagują na potrzeby zarządzania coraz bardziej złożonymi informacjami, które częściowo zwiększyły się w wyniku niedawnego wejścia w życie dyrektywy PSD 2.
Omawiane techniki umożliwiają maksymalne zwiększenie wartości danych oraz zapewniają nieocenioną przewagę konkurencyjną. Po pierwsze w świetle gwałtownego rozwoju konkurencji, gdzie na arenie pojawiają się nowi gracze. Po drugie źródeł danych, które są większe i łatwiejsze do zintegrowania. Po trzecie nowych modeli bankowości otwartej, znacząco zmieniających metody zarządzania klientami i ich angażowania.
Więcej informacji - zapraszamy do kontaktu: Daniel Skiba | e-mail: d.skiba@crif.com | tel: +48 606 754 923
Addo P., Guegan D., Hassani B. (2018) Credit risk analysis using machine and deep learning.
Breiman, L. (2001). Random forests. Mach Learn, 45:5-32.
Khandani, A.E., Kim, J., Lo, A.W. (2010). Consumer credit-risk models via machine-learning algorithms
Khashman, A. (2010). Neural networks for credit risk evaluation: Investigation of different neural models and learning scheme
Kruppa, J., Schwarz, A., Arminger, G., Ziegler, A. (2013). Consumer credit risk: Individual probability estimates using machine learning
Malley, J. D., Kruppa, J., Dasgupta, A., Malley, K. G., & Ziegler, A. (2012). Probability
machines: consistent probability estimation using nonparametric learning machines. Methods Inf Med 51:74-81
Martin Riedmiller, Heinrich Braun (1993). A Direct Adaptive Method for Faster Backpropagation Learning: The RPROP Algorithm. IEEE International Conference On Neural Networks. Vol. 16, pp.586—591
Nembrini, S., Koenig, I. R. & Wright, M. N. (2018). The revival of the Gini Importance? Bioinformatics
Tsai, C.F., Chen, M.L. (2010). Credit rating by hybrid machine learning techniques
Wright, M.N. & Ziegler, A. (2017). ranger: A fast implementation of random forests for high dimensional data in C++ and R.
Zhao, Z., Xu, S., Kang, B.H., Kabir, M.J., Liu, Y., Wasinger, R. (2015). Investigation and improvement of multi-layer perceptron neural networks for credit scoring